


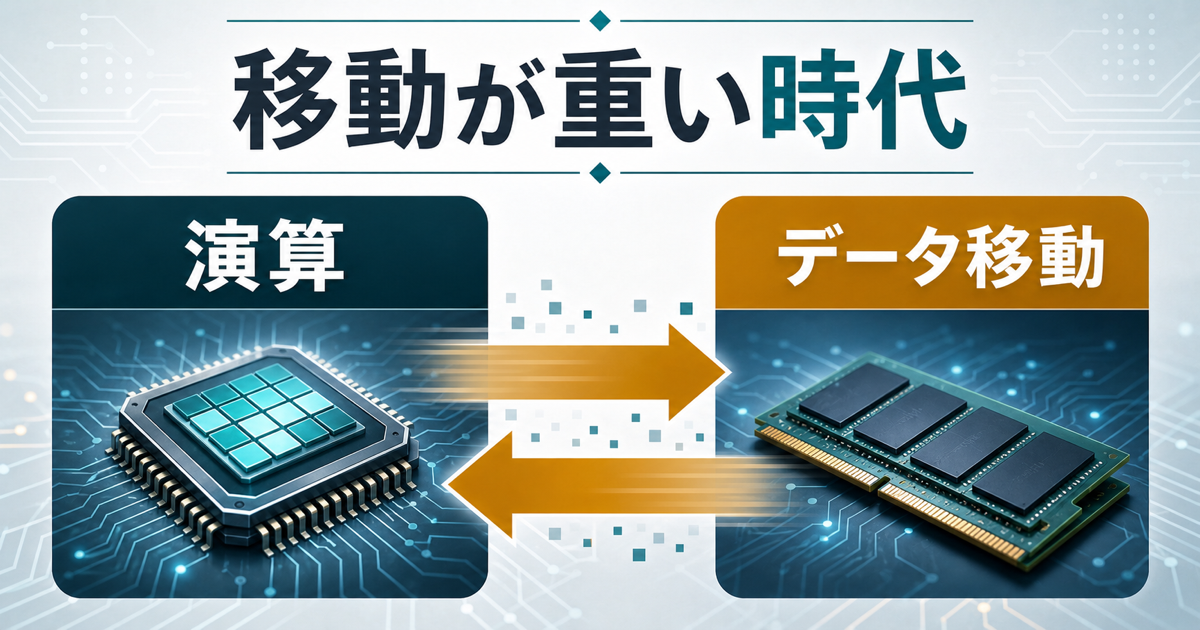
AIの半導体というと、どうしてもGPUやNPUのような「計算するチップ」に目が向きます。計算が速ければAIも速い。そう考えるのは自然です。ところが、AI推論の現場では少し違う問題が目立つようになってきました。計算する前に、データをどこからどこへ運ぶのか。その移動に時間と電力がかかるのです。
巨大な倉庫で作業する人を想像するとわかりやすいかもしれません。作業員がどれほど優秀でも、必要な部品が毎回遠くの棚にあるなら、仕事は移動で止まります。AIチップでも似たことが起きます。演算器は速くなっているのに、重みデータや中間データをメモリから運ぶたびに、時間と電力が削られる。半導体の世界では、この「運ぶコスト」が静かに重くなっています。
そこで出てくる考え方が、メモリ中心アーキテクチャです。中でもProcessing in Memory、略してPIMは、データを演算器へ何度も運ぶのではなく、メモリの中やメモリのすぐ近くで計算する発想です。派手な言葉にすると「メモリの中でAIが動く」と言いたくなりますが、ここは少し落ち着いて見たいところです。正確には、メモリ側に簡単な計算機能を持たせ、データ移動を減らす設計です。
この話は、以前扱ったシリコンフォトニクスやアナログコンピューティングともつながっています。光で速く運ぶのか、計算方式を変えるのか、それともデータを動かさないのか。AI推論の未来は、単純な性能競争ではなく、こうした複数の解き方が重なる方向へ進みそうです。
なぜメモリ中心アーキテクチャが注目されるのか
AI推論の壁は計算だけではない
AI推論では、モデルの重み、入力データ、中間結果が何度も読み書きされます。画像認識でも音声認識でも生成AIでも、計算そのものと同じくらい、データの取り回しが重要になります。
従来のコンピュータは、ざっくり言えば「計算する場所」と「記憶する場所」が分かれています。CPUやGPUが計算し、DRAMやHBMなどのメモリがデータを持つ。構造としてはわかりやすいのですが、AIのように大量のデータを何度も読む処理では、両者の往復が負担になります。
この問題は、フォン・ノイマンボトルネックと呼ばれる古い宿題にもつながります。計算装置とメモリの間の移動が性能を制約する、という話です。AI時代になって突然生まれた問題ではありません。ただ、AIモデルが大きくなり、推論回数が増えたことで、いよいよ見過ごしにくくなったというほうが近いでしょう。
速く運ぶだけでは足りなくなってきた
HBMのような高帯域メモリは、この問題に対する強力な答えです。データをより広い道路で運ぶ。これは短期的にも非常に重要です。実際、AIサーバーではHBMの供給や世代交代が大きな話題になっています。
ただし、道路を広げても、移動そのものが消えるわけではありません。そこで別の発想が出てきます。運ぶ距離を短くする。あるいは、運ばずにその場で処理する。この方向に進むと、メモリは単なる保管場所ではなく、計算の一部を担う場所になります。
ここがメモリ中心アーキテクチャの面白いところです。AI半導体の主役を「演算器だけ」から「演算器とメモリの配置」へ広げる。チップの未来を考える視点が、少し立体的になります。
3つの解決策は別々の道路を走っている
AI推論のデータ移動問題には、いくつかの解き方があります。
- 光配線やシリコンフォトニクスで、データを速く遠くへ運ぶ
- アナログコンピューティングで、計算方式そのものを変える
- PIMで、メモリの中や近くで処理して移動を減らす
どれかひとつが全部を置き換えるというより、用途によって組み合わされると見るほうが自然です。データセンターではHBMや光接続、エッジAIでは低消費電力なPIMやアナログ計算。そんなふうに、場所ごとに最適解が変わっていくはずです。
Processing in Memoryは何をする技術なのか

広義のPIMとして整理しておく
Processing in Memoryという言葉は、少しやっかいです。厳密には、メモリセルそのものの中で計算するCompute-in-Memory、メモリの近くに計算機能を置くProcessing Near Memory、メモリに演算機能を統合する設計など、いくつかの考え方があります。
ここでは、ビジネス読者にも見通しが持てるように、広義のPIMとして扱います。つまり「データを遠くの演算器へ運ぶ回数を減らすため、メモリ側またはメモリ近傍で処理する設計」として整理します。この定義なら、細かな実装方式の違いに迷わず、未来の半導体設計を読めます。
従来型との違いは往復の少なさにある
従来型では、データはメモリから演算器へ送られ、処理され、またメモリへ戻ります。この往復が何度も起きます。PIMでは、メモリの中や近くに簡単な計算機能を置き、すべてのデータを遠くへ運ばなくても済むようにします。
もちろん、PIMが高性能GPUの代わりに何でも計算するわけではありません。複雑な制御や大規模な演算は、引き続きCPU、GPU、NPUが担います。PIMが得意なのは、メモリに近い場所で繰り返し行う処理です。倉庫でいえば、部品を作業台まで毎回運ぶのではなく、棚の近くで簡単な仕分けを済ませるイメージです。
AI推論で効きやすい理由
AI推論、とくにニューラルネットワークの処理では、重みデータを読みながら大量の積和演算を行います。モデルが大きくなるほど、メモリからデータを読む回数も増えます。そこで、データの近くで一部の演算を済ませられれば、移動コストを減らせる可能性があります。
この「可能性」という言葉は大切です。PIMは魔法の近道ではありません。ソフトウェア、コンパイラ、メモリ規格、製造コスト、既存のGPUシステムとの接続がそろって初めて、実用の場が広がります。ただ、AI推論の回数が増えるほど、メモリ側で処理したいという圧力は強くなります。
HBMとCXLの先にあるメモリ設計を分けて見る
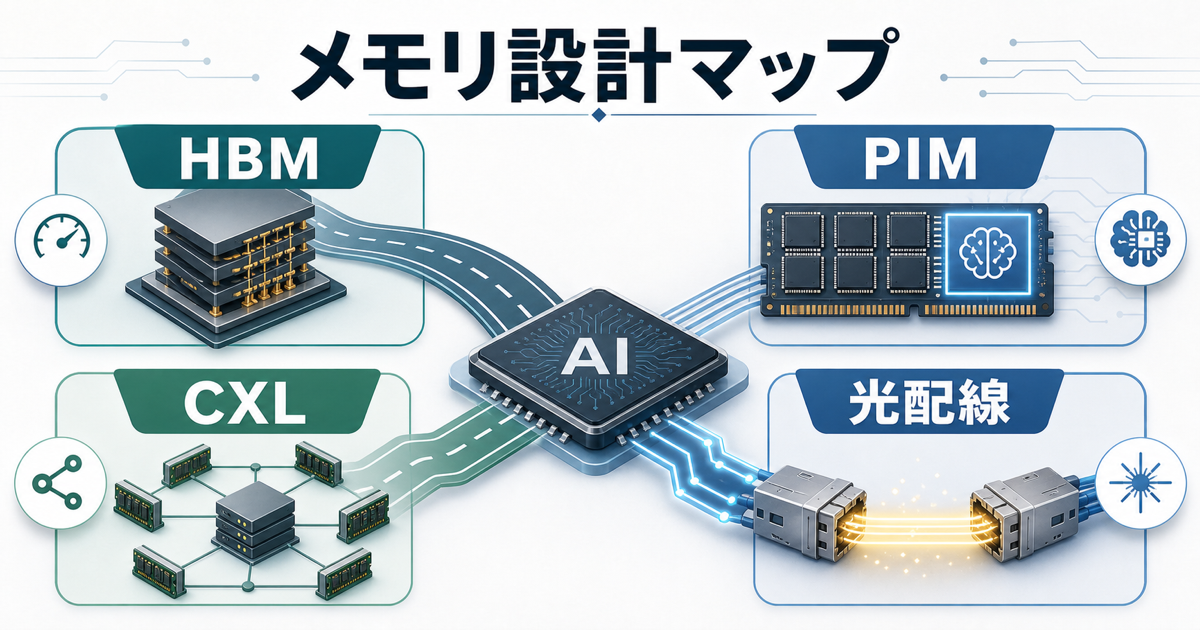
HBMは広い道路、PIMは移動しない工夫
HBMは、AIサーバーにとって重要な高帯域メモリです。道路のたとえで言えば、メモリと演算器の間の道を太くする技術です。これは非常に強い解決策ですが、PIMとは役割が違います。
HBMが「速く運ぶ」なら、PIMは「運ぶ前に処理する」または「運ぶ量を減らす」方向です。両者は対立するものではありません。SamsungはHBM-PIMとして、HBMにAI処理機能を統合する取り組みを発表しています。ここから見えるのは、メモリの高速化とメモリ内処理が同じ方向へ合流する未来です。
CXLはメモリを共有する道具でPIMとは別物
CXL、Compute Express Linkもメモリ中心の話でよく出てきます。CXLは、CPUとデバイス、メモリを高速につなぎ、データセンターでメモリを柔軟に使うための規格です。メモリプーリングや共有メモリの文脈で語られます。
ただし、CXLとPIMは同じではありません。CXLはメモリをどう接続し、どう共有するかの話です。PIMはメモリ側で処理を行い、データ移動を減らす話です。両者は将来的に組み合わさる可能性がありますが、混ぜてしまうと見通しが悪くなります。CXLは交通網、PIMは倉庫内の作業台。私はそんなふうに分けて見ると理解しやすいと思います。
比較して見ると位置づけがはっきりする
| 技術 | 主に解く問題 | 得意な場面 | 注意点 |
|---|---|---|---|
| HBM | メモリ帯域を広げる | 大規模AIサーバー | 供給、コスト、実装密度 |
| PIM | データ移動を減らす | メモリに近い反復処理 | ソフトウェア対応と用途選定 |
| CXL | メモリを柔軟につなぐ | データセンターのメモリ共有 | PIMとは役割が違う |
| 光配線 | 遠距離・高帯域の接続 | チップ間、ラック間通信 | 実装コストと量産段階 |
| アナログ計算 | 計算方式を変える | 低消費電力推論 | 精度、ばらつき、設計難度 |
この表で見たいのは、どれが一番優れているかではありません。問題の置き場所が違う、ということです。AI半導体の未来は、ひとつの万能チップよりも、複数の技術をどこで使うかの設計に近づいていきます。
PIMの実装はどこまで進んでいるのか
SamsungとSK hynixはメモリ側から動いている
PIMは研究室だけの言葉ではありません。SamsungはHBM-PIMを発表し、HBM2 AquaboltにAI処理機能を統合する方向を示しました。発表では、既存HBM2を使うシステムと比べた性能向上やエネルギー削減の効果も示されています。ただし、本文ではその数値を未来のすべてのPIMに広げて扱うことは避けます。特定条件での発表値だからです。
SK hynixもGDDR6-AiMやAiMXとして、Accelerator-in-Memoryの取り組みを示しています。こちらも、AI処理をメモリに近づける流れのひとつです。重要なのは、メモリメーカーが単に容量や帯域を競うだけでなく、計算の一部を取り込もうとしている点です。
すぐに全AIサーバーがPIM化するわけではない
ここで焦ってはいけません。PIMが発表されているからといって、近いうちにすべてのAIサーバーがPIMへ変わるわけではありません。既存のGPUソフトウェア資産は巨大で、開発者は慣れた環境で性能を出したいからです。
PIMが広がるには、ハードウェアだけでは足りません。どの演算をPIMに任せ、どの処理をGPUやNPUに残すのか。コンパイラやランタイムがそれをうまく割り振れるのか。開発者が意識しすぎずに使えるのか。こうした周辺の仕組みが必要です。
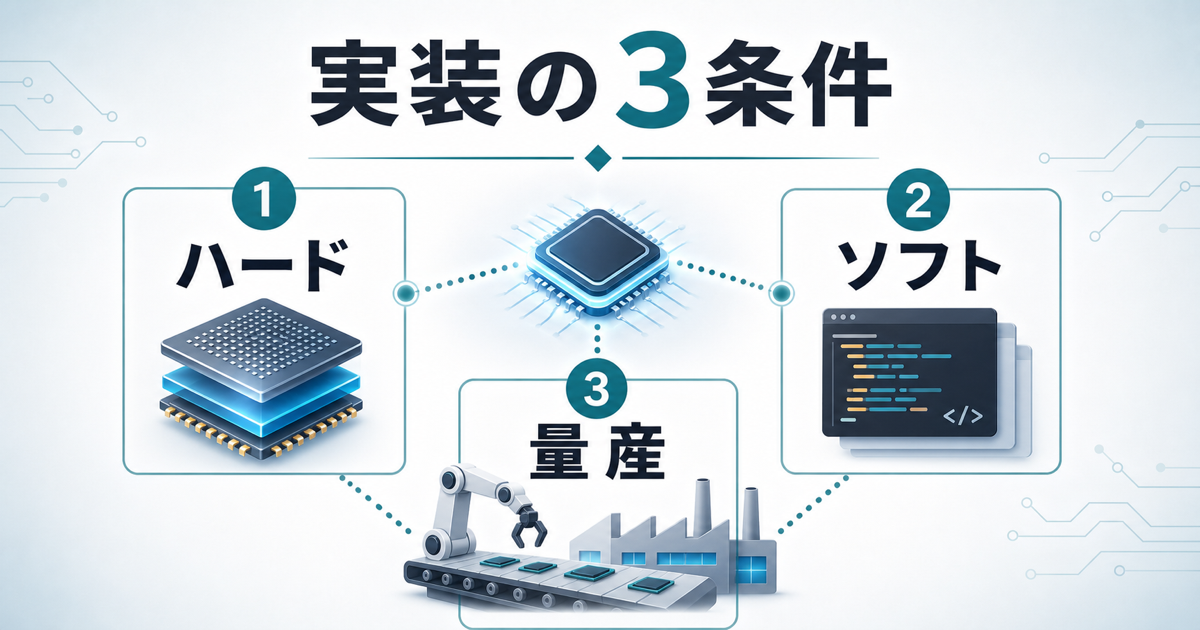
量産化の壁は技術より運用にある
PIMの難しさは、半導体の製造だけではありません。実装では、ハード、ソフト、量産という3つの条件をそろえる必要があります。ハードはメモリ側にどの処理を持たせるか、ソフトは開発者が意識しすぎずに使えるか、量産は歩留まりやコストを現実に合わせられるかです。
- 既存ソフトウェアとの互換性をどう保つか
- どのAIモデルで効果が出るかをどう見極めるか
- メモリ側の発熱や歩留まりをどう管理するか
- GPU、NPU、CPUとの役割分担をどう設計するか
だから、PIMは単体の部品として見るより、システム設計の変化として見るほうが近いです。チップを買えば終わりではなく、AI処理の流れをどこで区切るかまで考える必要があります。
メモリの中で処理する発想はどこに効いてくるか
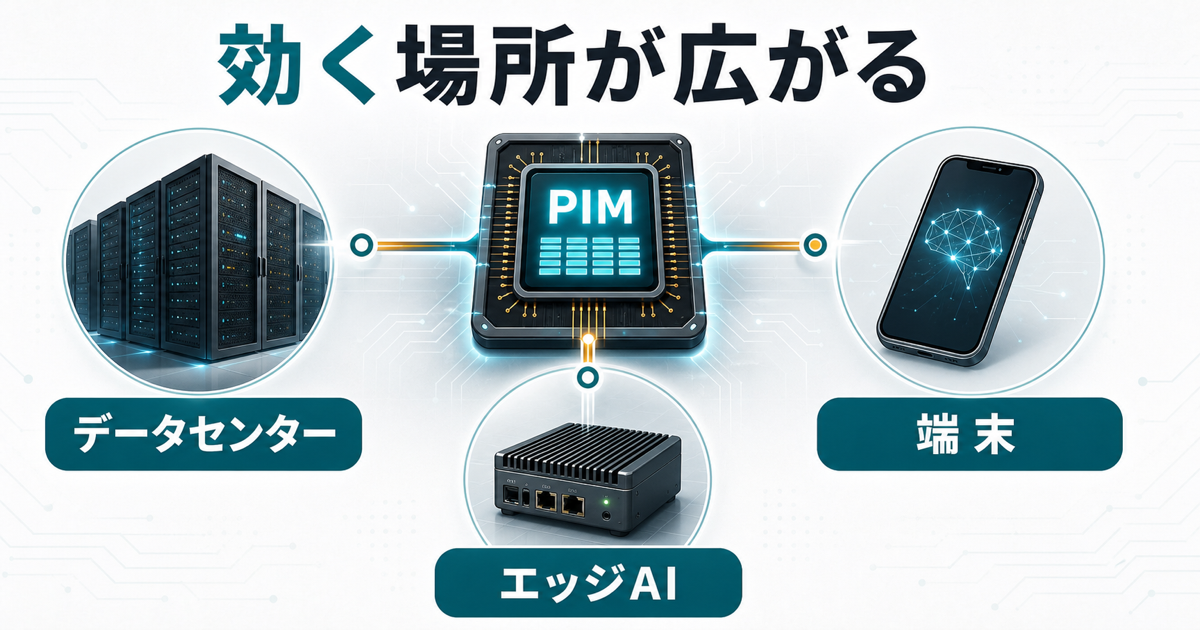
データセンターでは推論コストの圧力が強まる
生成AIやエージェント型AIが増えるほど、AI推論は一度きりの処理ではなくなります。ユーザーの問い合わせ、社内文書の検索、画像や音声の理解、ロボットの判断。さまざまな場所で、小さな推論が何度も走ります。
このとき、データセンターの電力と冷却は大きな制約になります。PIMが効く領域が広がれば、すべてではないにせよ、メモリに近い処理の電力を下げられる可能性があります。AIの未来は、より賢いモデルだけでなく、より無駄の少ない推論にも支えられます。
エッジAIでは小さな電力差が体験を変える
スマートグラス、家庭用ロボット、車載AI、工場センサー。こうしたエッジAIでは、消費電力や発熱が体験に直結します。サーバーなら冷却設備を増やせますが、眼鏡や小型ロボットではそうはいきません。
PIMは、こうしたエッジAIにも関係してきます。すべての演算をメモリ内で行うわけではなくても、繰り返し発生する軽い処理をメモリ近傍に寄せられれば、電池持ちや応答速度に効いてくるかもしれません。以前のスマート家電の常時推論の記事ともつながる話です。
仕事や生活に見える変化は静かに来る
メモリ中心アーキテクチャは、消費者が店頭で名前を見て選ぶ技術ではないでしょう。スマートフォンの箱に「PIM搭載」と大きく書かれる未来が来るかはわかりません。けれど、裏側では効いてきます。
AIアプリの応答が少し速くなる。端末が熱くなりにくくなる。クラウドの推論コストが下がり、今まで高価だったAI機能が日常のサービスに入りやすくなる。こうした変化は、見た目には地味です。でも、AIが生活に溶け込むとき、本当に重要なのはこの地味な改善だったりします。
PIMはAI半導体をハイブリッド設計へ押し出す

置き換えではなく役割分担が進む
PIMを語るとき、ひとつだけ避けたい見方があります。それは「GPUの役割が消える」「メモリが計算をすべて担う」といった置き換え論です。現実はもっと混ざり合っています。
CPUは制御を担い、GPUやNPUは大きな演算をこなし、HBMは高帯域でデータを供給し、PIMはメモリに近い処理を受け持つ。CXLのような接続技術は、メモリをより柔軟に配置する。光配線は距離がある場所を高速につなぐ。こうした役割分担が進むほど、AI半導体は単体性能よりもシステム設計の勝負になります。
半導体を見る目が少し変わる
これからAIチップを見るときは、演算性能の数字だけでなく、メモリがどこにあり、どれだけ近く、どれだけ賢く使われているかを見ると面白くなります。TOPSや帯域幅だけでは見えない設計思想が、そこに出るからです。
メモリ中心アーキテクチャは、AIの未来を少し地味な方向から押しています。派手な新モデルの発表ほど目立ちません。けれど、AIが何億回も推論され、身近な端末や工場や車の中で動くようになるほど、地味な効率化は強く効きます。
次にAI半導体のニュースを見るとき、「どれだけ速いか」だけでなく、「データをどれだけ動かさずに済ませているか」にも目を向けてみてください。AIの進化は、計算の速さだけでなく、動かさない設計の静かな工夫からも進んでいきます。







