


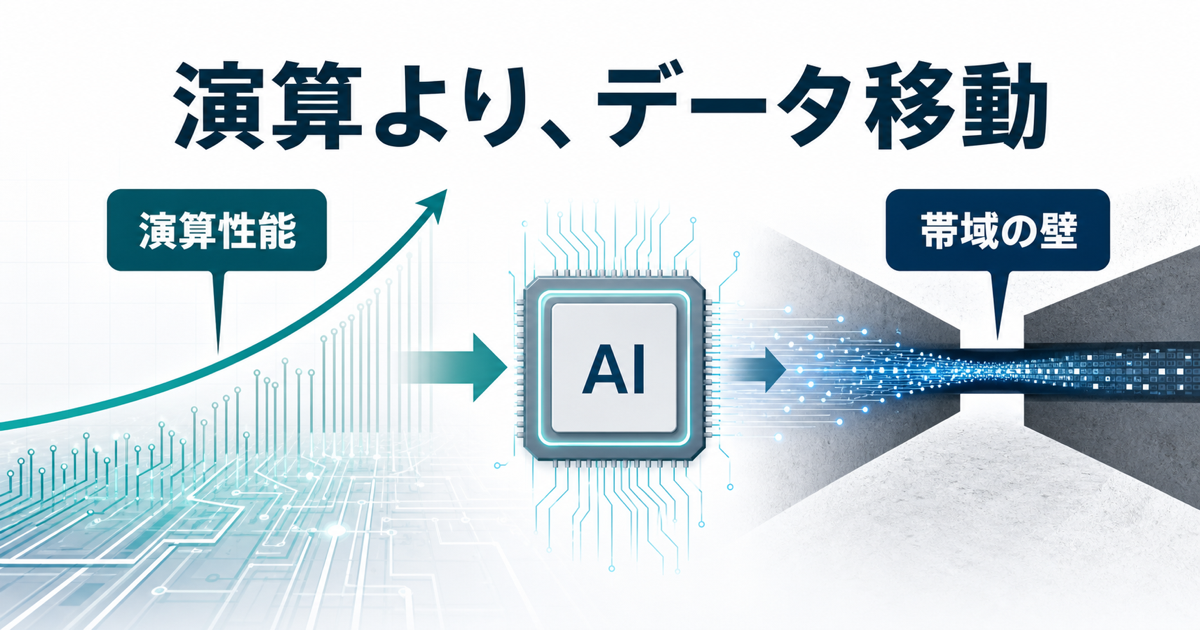
AI推論の次の壁は、計算そのものより「データをどれだけ無理なく動かせるか」に移り始めています。
GPUやNPUの性能が伸びても、モデルの重み、入力データ、中間結果がチップの外へ出入りするたびに、時間と電力がかかります。人間でいえば、頭の回転は速いのに、資料を取りに行く廊下が混んでいる状態です。AI推論の現場では、この廊下にあたる配線やインターコネクトが、じわじわと主役になっています。
そこで注目されるのが、光集積回路とシリコンフォトニクスです。光を使えば何でも一瞬で解決する、という単純な話ではありません。光の強みは「速い」というより、高い帯域を扱いやすく、距離が伸びても損失を抑えやすく、波長を分けて多くの信号を同時に運べる点にあります。この記事では、AI推論の帯域がなぜ問題になるのか、光集積回路がどこで効くのか、そして銅配線とどう棲み分けるのかを整理します。
演算ではなく配線が遅い AI推論の本当のボトルネック
モデルが大きくなるほどデータ移動が重くなる
AI推論では、学習済みモデルを使って入力に対する答えを出します。文章生成、画像認識、翻訳、ロボット制御、スマート家電の常時推論まで、推論そのものは私たちの生活に近い場所へ広がっています。ところが、モデルが大きくなるほど、演算器だけを増やしても効率は上がりにくくなります。
理由は、演算器が必要とするデータを絶えず届けなければならないからです。チップ内、チップ間、メモリとの間、サーバー同士の間でデータが行き来します。生成AIの応答が遅い、クラウド費用が高い、データセンターの電力が増える。こうした問題の奥には、計算量だけでなく、データ移動のコストがあります。
「光が速い」よりも大事な帯域と損失
ここで注意したいのは、光集積回路を「光だから速い」とだけ説明すると本質を見誤ることです。AI推論で大切なのは、真空中の光速の話ではありません。大量のデータを、限られた電力とスペースでどれだけ安定して運べるかです。
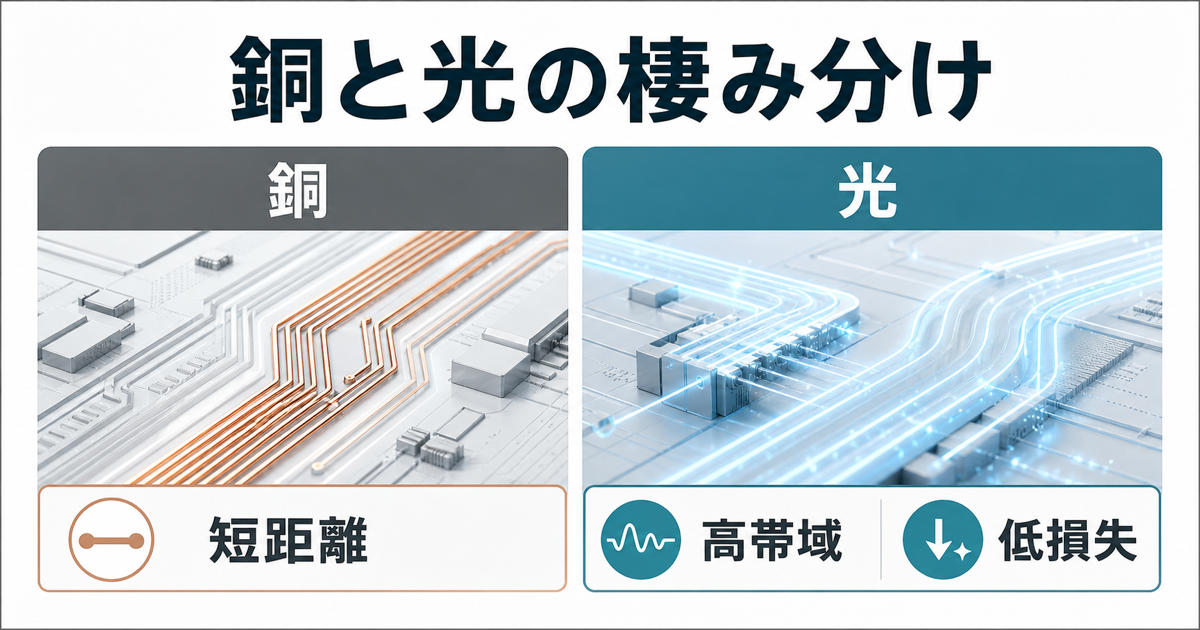
銅配線は短い距離では強力です。成熟していて安く、実装ノウハウも豊富です。一方で、データレートが上がり、距離が伸び、配線本数が増えるほど、信号劣化や発熱、ピン数、基板設計の制約が重くなります。光はこの領域で、帯域を広げるための別ルートになります。つまり、銅を消す技術ではなく、銅だけでは苦しくなる場所に入ってくる技術です。
この変化は、読者にとっても意外と近い話です。AIサービスの応答が数秒遅れる、クラウド利用料が高止まりする、企業が社内AIを入れたいのにサーバー費用で迷う。こうした体験は、表面上はアプリの問題に見えて、奥では配線、メモリ、パッケージ、冷却が絡み合っています。だから私は、光集積回路を「半導体ニュースの細部」ではなく、AIが日常へ広がるためのインフラ技術として見ています。
光集積回路とシリコンフォトニクスは何をする技術か
電気信号を光に変えてチップの近くで運ぶ
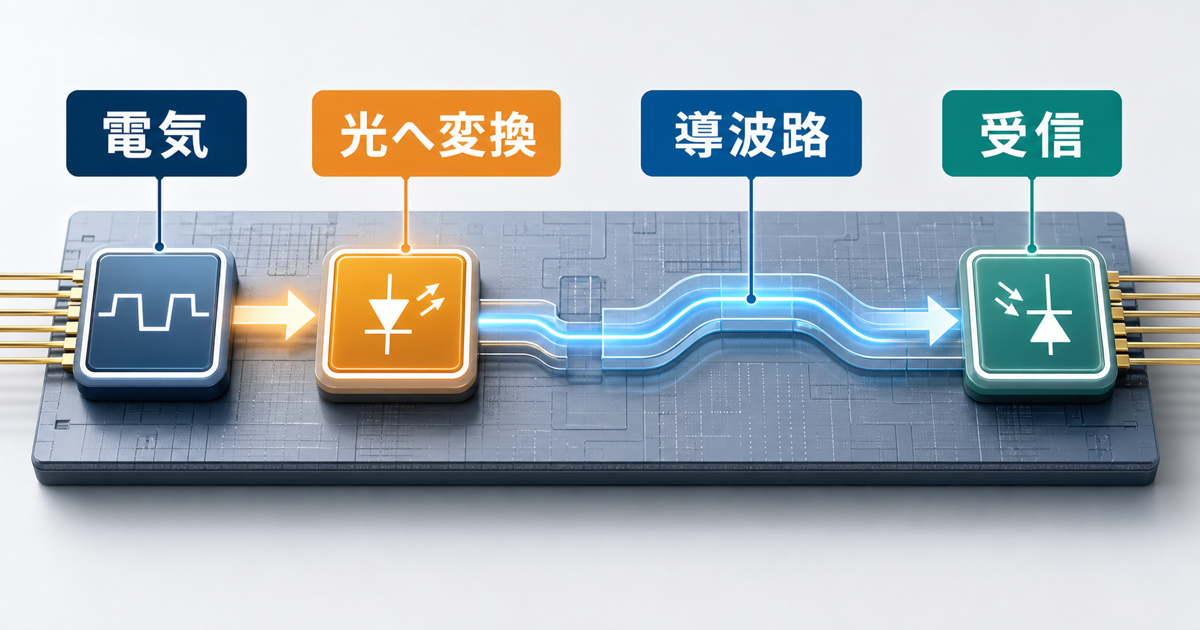
光集積回路、PICは、光を扱う部品を1つのチップ上に集める考え方です。変調器、導波路、受光器などを組み合わせ、電気信号を光信号へ変え、必要な場所へ運び、また電気信号へ戻します。データセンターの光トランシーバでは、この考え方はすでに身近です。
シリコンフォトニクスは、その光回路をシリコン半導体の製造技術に近い形で作ろうとする領域です。シリコン基板上に光の通り道を作り、既存の半導体製造エコシステムに乗せやすくする。ここに大きな意味があります。AIチップの隣に光の入出力を置ければ、電気信号だけで長い距離を引き回す負担を減らせるからです。
レーザーや実装はまだ単純ではない
ただし、シリコンフォトニクスを「すべてシリコンだけで完結する技術」と見るのは少し危ういです。光源にはレーザーが必要で、III-V族材料などとの組み合わせや外部光源の利用が関わります。チップと光ファイバーの位置合わせ、熱による波長のずれ、検査工程も簡単ではありません。
私はここが、シリコンフォトニクスを面白くしている部分だと思います。AI時代の半導体は、演算器だけを磨く競争から、パッケージ、光、メモリ、冷却、ソフトウェアまで含めた総合設計へ移っています。以前の記事で触れたフィジカルAIと次世代半導体の流れも、まさにこの総合戦に近づいています。
なぜ光でAI推論の帯域が変わるのか
銅配線は短距離に強く長距離で苦しくなる
銅配線の弱点は、悪者だから生まれるのではありません。物理的に、抵抗、容量、信号の反射、ノイズ、発熱があるからです。短距離なら制御しやすい問題でも、チップ間、ボード間、ラック間へ伸びるほど補正が必要になります。補正回路を増やせば電力を使い、電力を使えば冷却も重くなります。
AI推論基盤では、1つのチップだけで完結しない処理が増えます。複数のアクセラレータ、メモリ、ネットワーク機器が協調し、必要に応じてデータを渡し合います。このとき、演算器が待たされる時間が増えると、高価なAIチップを積んでも能力を使い切れません。高性能な調理人を何人も雇ったのに、食材の搬入口が1つしかない厨房に似ています。
光は波長を分けて1本の通り道に信号を重ねられる
光の強みのひとつは、波長分割多重です。異なる波長の光を使うことで、1本の光ファイバーや導波路に複数の信号を重ねられます。道路でいえば、同じ道に複数の専用レーンを作るようなものです。これにより、配線本数を増やすだけに頼らず、帯域を拡張しやすくなります。
もちろん、光へ変換する送受信回路は必要です。変換に電力もかかります。そのため、すべての距離で光が勝つとは限りません。ごく短い距離なら銅のほうが合理的な場面は残ります。光が効きやすいのは、データレートが高く、距離があり、配線密度や電力が厳しい場所です。
| 比較軸 | 銅配線 | 光配線 |
|---|---|---|
| 得意な距離 | チップ内や短い基板内で強い | 距離が伸びても損失を抑えやすい |
| 帯域の広げ方 | 配線本数や信号処理を増やす | 波長多重で信号を重ねやすい |
| 消費電力 | 短距離では有利な場面が多い | 長距離・高帯域では有利になり得る |
| 実装成熟度 | 非常に高い | 用途により実用段階と開発段階が混在 |
| AI推論での役割 | 近距離の接続を支える | チップ間・ラック間の帯域拡張を担う |
光が効く3つのシーン
AI推論で光集積回路が効きやすい場所は、いきなりすべてのチップ内ではなく、段階的に広がると見るのが自然です。
- ラック間やサーバー間の高速接続。大量の推論リクエストをさばくデータセンターで、距離と帯域の両方が問題になる。
- AIアクセラレータ同士の接続。複数チップで1つのモデルを動かすとき、演算器を待たせないことが重要になる。
- メモリやI/Oに近い領域。メモリ帯域の不足が推論性能を制限する場面で、光I/Oが選択肢になる。
家庭のスマート家電のような小さなエッジAIでは、すぐに光配線が入るわけではありません。ただ、クラウド側の推論基盤が効率化すれば、サービス費用や応答速度の形で生活側にも影響が届きます。以前のスマート家電とエッジAIチップの電力問題も、遠くで動くデータセンターの効率と無関係ではありません。
CPOと光I/Oはどこまで実装が進んでいるのか

光トランシーバは実用 CPOは次の近づけ方
シリコンフォトニクスは、遠い未来だけの研究テーマではありません。データセンターの光トランシーバでは、すでに実用領域に入っています。一方で、AIチップのすぐ近くに光入出力を寄せるCPO、Co-Packaged Opticsや、光I/Oチップレットは、実装が進みつつある段階です。ここを混ぜて語ると、過大評価にも過小評価にもなります。
Open Compute ProjectのCo-Packaged Opticsは、光をスイッチASICなどの近くへ持っていく発想を整理する場になっています。IntelもIntegrated Optical I/O chipletをAIインフラ向けの研究開発として示しています。こうした動きは、演算チップ単体の性能競争から、チップ周辺のデータ移動を含む設計競争へ移っていることを物語ります。
量産の壁は歩留まりと温度と検査にある
光I/OをAI推論基盤に広げるには、単に試作品が動けばよいわけではありません。量産で安定して作れるか、パッケージ内で精密に位置合わせできるか、熱で特性が変わらないか、出荷前にどう検査するかが問われます。半導体は、研究室で美しく動くことと、何百万個も同じ品質で出荷することの間に深い谷があります。
ここで効いてくるのが、パッケージングとエコシステムです。光集積回路は、AIチップ、メモリ、基板、冷却、ネットワーク装置と一体で考える必要があります。だからこそ、半導体メーカーだけでなく、ハイパースケーラー、装置企業、光部品メーカー、スタートアップまでが関わる領域になります。
もうひとつ見落としたくないのは、標準化です。AIインフラは1社の部品だけで閉じません。スイッチ、アクセラレータ、光モジュール、サーバー、運用ソフトがつながって初めて価値を出します。CPOや光I/Oが広がるには、性能だけでなく、交換しやすさ、保守しやすさ、複数ベンダーで組み合わせられる安心感も必要です。未来の勝負は、最高速の一点突破だけでなく、現場が長く使える設計を作れるかにもあります。
銅と光は置き換えではなく役割分担へ進む
「光が来るなら銅は終わり」と考える必要はありません。むしろ現実的なのは、短距離は銅、高帯域で距離が伸びる場所は光、という棲み分けです。半導体の歴史では、古い技術が消えるより、得意な場所へ残ることがよくあります。HDDが完全に消えず、SSDと用途を分けたように、銅配線もAIインフラの中で居場所を持ち続けるはずです。
AI推論の未来で読者が見るべき変化

学習より先に推論インフラで効く可能性がある
光集積回路は学習にも関わりますが、読者目線で変化を感じやすいのは推論インフラかもしれません。AIサービスは、使われるほど推論回数が増えます。検索、要約、翻訳、コード生成、画像生成、業務エージェント、ロボット制御。利用回数が増えるほど、1回あたりの推論コストを下げることが重要になります。
この流れは、宇宙空間の計算基盤のような遠いテーマにもつながります。宇宙データセンターとAI推論の可能性を考えるときも、電力、冷却、通信、データ移動は避けて通れません。地上のデータセンターで起きている帯域の課題は、未来の計算インフラ全体を読む手がかりになります。
製品ニュースを見るときはチップ性能だけでなく接続を見る
これからAI半導体のニュースを見るとき、TOPSやGPU数だけで判断すると見落としが増えます。どのメモリを使うのか。どのパッケージ技術を採るのか。チップ同士をどうつなぐのか。ラック内のネットワークはどう設計されるのか。シリコンフォトニクスが入るかどうかは、その製品が「単体の速さ」から「群れとしての効率」へ進んでいるかを見るサインになります。
特に法人向けAI、クラウドAI、エッジとクラウドを組み合わせるサービスでは、データ移動の設計がユーザー体験へ跳ね返ります。応答が速い、料金が下がる、発熱が減る、設置できる場所が増える。そうした変化は、派手なチップ名より少し遅れて、しかし確実に私たちの手元へ届きます。
個人が今すぐシリコンフォトニクス搭載製品を選ぶ場面は、まだ多くありません。それでも、AIサービスを選ぶ企業、クラウド費用を見直す担当者、エッジAI機器の将来を追う人にとっては、早めに見ておきたい変化です。演算性能だけを見ていた時代から、データを動かす設計まで読む時代へ。そこに気づけると、AI半導体のニュースはずっと立体的に見えてきます。
次にAIチップやデータセンターの発表を見かけたら、演算性能の数字の横にある「どうつないでいるのか」を少しだけ眺めてみてください。光集積回路の本当の面白さは、AIを速く見せることではなく、AIが社会のあちこちで無理なく動き続けるための通り道を広げるところにあります。







